Why Traffic Manipulation Capabilities Matter
December 5, 2017
ops
kubernetes
Multi-tenancy systems are very common for a simple reason: it both saves costs, and reduces complexity. Unfortunately, the biggest downside is that in certain situations, a small group of clients can negatively impact the rest of the system.
At Cratejoy, we run with a multi-tenant set up which is part SaaS, part Marketplace, and part Website Hosting. These 3 sections of our business have drastically different traffic patterns. Even within out Website Hosting, our individual merchants see extremely different traffic patterns. When hosting multiple tenants, or multiple applications, you must have a plan to guarantee that a single (or small number of) tenant(s)/application(s) cannot negatively impact the rest.
No matter how hard you try, you will not be able to prepare for any event. Even if you can handle any legitimate amount of traffic, it is always possible that you, one of your services, or one of your hosted clients is targeted by an attack. Having the capability to quickly isolate the rest of your platform from these events is key. Depending on your deployment architecture, this may or may not be easy.
In preparation for these events, we run a secondary (scaled down) standby deployment in parallel to our main deployment, which sits behind it’s own AWS Target Group. By being able to quickly route specific customer traffic to separate resources, we can isolate the majority of our platform in a matter of minutes. It’s as simple as adding Load Balancer Routing Rules for a given domain, or specific path, and targeting the standby Target Group.
While there are other possible ways to handle these situations (such as blackhole-ing traffic), we prefer a solution which attempts to fulfill the influx of traffic. After this adding the Routing Rules, the main deployment (still receiving the rest of platform traffic) is able to recover, while the separate deployment attempts to serve the isolated traffic.
While this solution does not work in every situation, and does not necessarily mean a recovery for the redirected traffic, we’ve found it very effective at isolating risks, and ensuring availability of the rest of the platform.
As an example, the image below is a traffic graph of a situation that this approach proved helpful in.
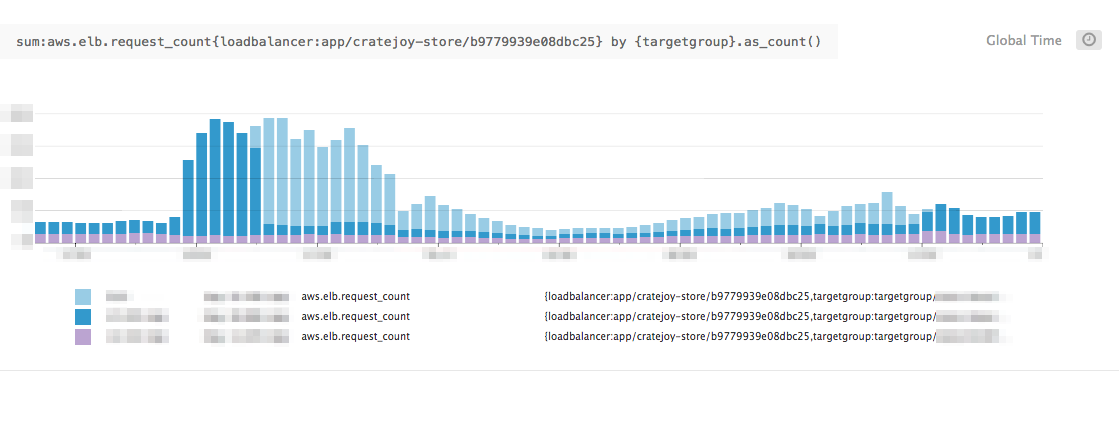
While we were initially seeing degraded performance across all clients, with a rather high error rate, isolating the sources of the majority of the traffic (light blue) was able to restore the majority of our service, giving us breathing room to focus on quick optimizations for the still-impacted clients.
Hopefully this works out for you, or was at least helpful. If you have any questions, don’t hesitate to shoot me an email, or follow me on twitter @nrmitchi.