Importance of Index Monitoring
December 5, 2017
ops
postgres
Monitoring is a a large, and complex topic, so rightfully is a a lot written about it. One topic that is not covered often however, is effectively monitoring your database indexes. This particular aspect of monitoring is something that had not previously occurred to me as something important, however one incident was rather eye-opening.
We have recently been dedicating resources to focussing on db performance issues, and had finally gotten to a point where our CPU was consistently < 30%, our disk operations were consistently below our waterlines, and our Read Replica Replication Lag was consistently < 1s. This is was we considered to be a good place. It allowed us to focus on application performance, with trust that our database was relatively safe.
It All Goes Bad
Unfortunately, these metrics all started to degrade one day. Our CPU usage rose, and our Replication Lag began ‘saw-blading’ (ie, would grow to a max, then suddenly drop when it hit the max_replication_delay). An increase in either of these metrics would typically indicate a long-running query against the main, or read-replica databases respectively, so it was weird seeing both begin at the same time.
Our main mistake here was defaulting to the assumption that we had broken something. The fact that both databases were affected, as well as the fact that the problem began in the middle of the night, should have been an indication that it was not.
Due to our lack of monitoring, it took us much longer than necessary to find the problem
The Root Problem (and easy solution)
Our break came when we came across this:
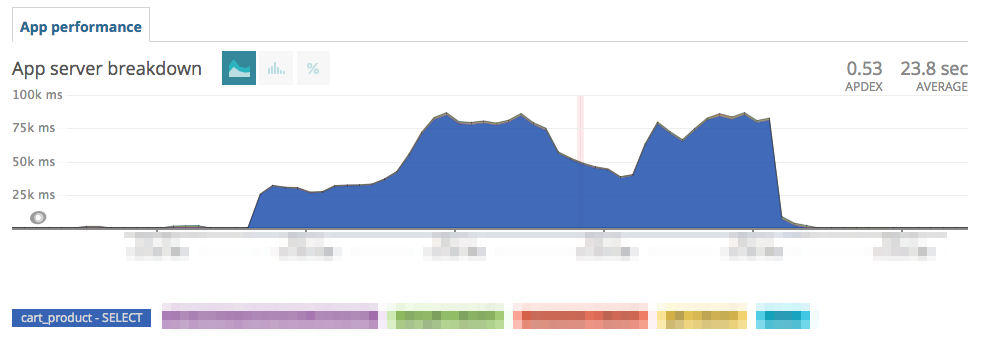
The extreme amount of time spent in this particular query led to to an explain, where we saw that the index was not being used. Unfortunately though, this still did not point us to the root cause. That came when we got lucky, in that we ran a \d <table> for another purpose, and saw that the index was listed as INVALID.
Prior to this, the possibility of a corrupt index had not even occured to us. With this knowledge though, we were able to replace the index, and performance returned to normal.
Lessons Learned
In the end, a few things were learned here:
- You should always be monitoring for
INVALIDindexes, since it will almost always mean something is wrong.
-- Postgres Query to Get Invalid Indexes
SELECT n.nspname, c.relname
FROM pg_catalog.pg_class c, pg_catalog.pg_namespace n,
pg_catalog.pg_index i
WHERE (i.indisvalid = false OR i.indisready = false) AND
i.indexrelid = c.oid AND c.relnamespace = n.oid AND
n.nspname != 'pg_catalog' AND
n.nspname != 'information_schema' AND
n.nspname != 'pg_toast'
- You can get the create statement for an index (by name) from the
pg_indexesview. - You can replace an index by recreating (with a new name), drop the one old, and if you’d like, rename the new index to the old name.
- When dropping an invalid index, even though it is not being used, you should still do it
CONCURRENTLY, because it can still block. - After replacing indexes, you will likely have to run an
ANALYZEon the affected table. - You should be monitoring for unused indexes. These may mean that something is wrong.
Hopefully this works out for you, or was at least helpful. If you have any questions, don’t hesitate to shoot me an email, or follow me on twitter @nrmitchi.